Authors
Ryo Terashima
Ryuichi Yamamoto
Kentaro Tachibana
Abstruct
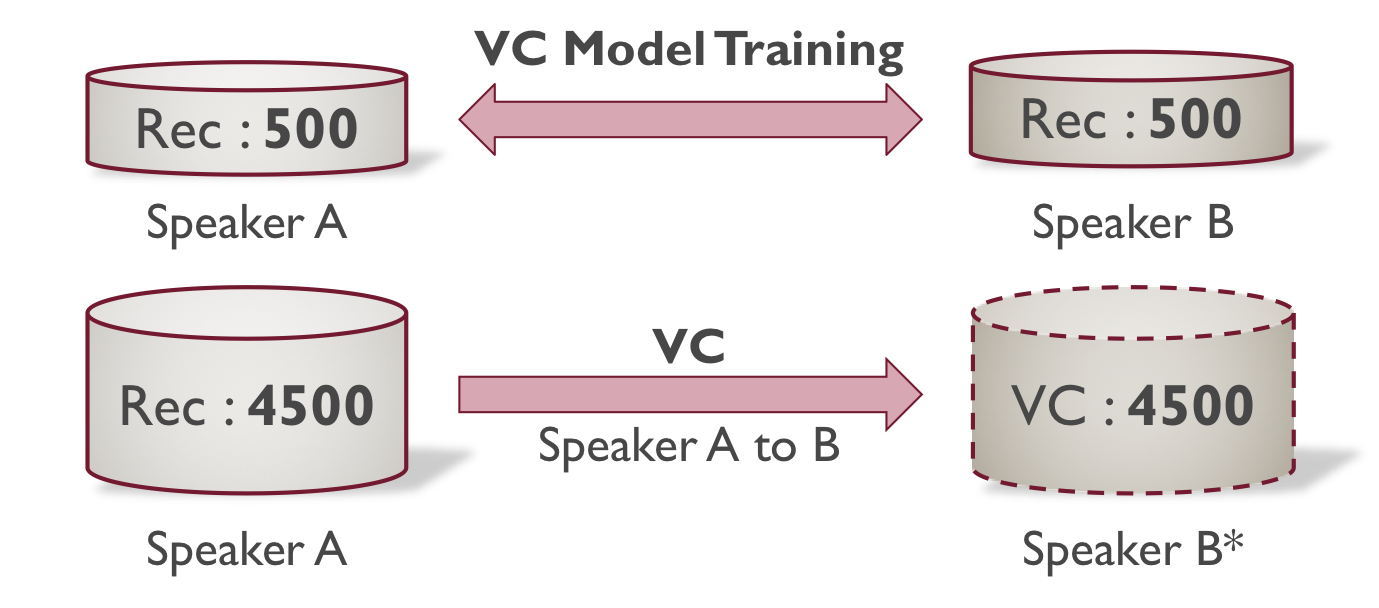
特定話者の数千発話のデータを用いて,高品質なテキスト音声合成 (text-to-speech; TTS) を実現することが可能である.その一方,数千発話規模の音声収録やアノテーションにかかるコストは大きい.本稿では,対象話者 (Speaker B) の少量のデータから TTS モデルを構築するために,他話者 (Speaker A) とのデータ間で声質変換 (voice conversion; VC) を行い,対象話者のデータを拡張する方式の検討を行った.
Subjective Evaluation
Models
Model
Type
VC Training [utts]
TTS Training [utts]
Natural Recorded audio (Speaker B)
-
-
VC Source Recorded audio (Speaker A)
-
-
TTS:500 TTS
-
500(Rec)
TTS:5000 TTS
-
5000(Rec)
TTS:500+VC4500 TTS with VC data augmentation
500:500(Rec)
500(Rec)+4500(VC)
TTS:2500+VC2500 TTS with VC data augmentation
2500:2500(Rec)
2500(Rec)+2500(VC)
VC: Scyclone [1]TTS: FastSpeech 2 [2]Vocoder: Harmonic-plus-noise Parallel WaveGAN [3]
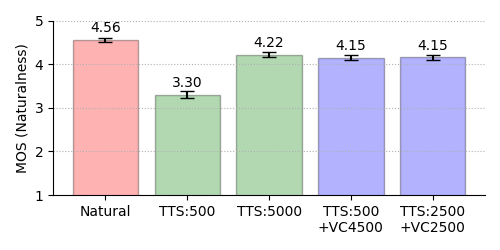
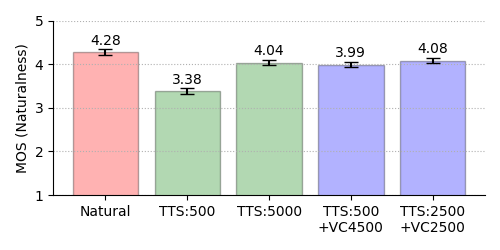
5-Point MOS Results on Naturalness
Female
Male
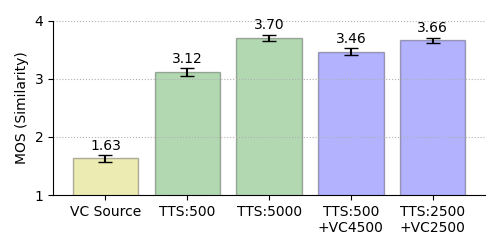
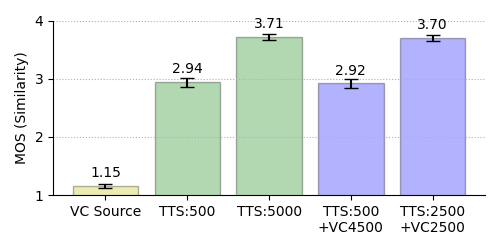
4-Point MOS Results on Similarity
Female
Male
Audio Samples
Sample 1
Model
Female
Male
Natural
VC Source
TTS:500
TTS:5000
TTS:500+VC4500
TTS:2500+VC2500
Sample 2
Model
Female
Male
Natural
VC Source
TTS:500
TTS:5000
TTS:500+VC4500
TTS:2500+VC2500
References
[1]: 金垣葵, 田中雅也, 能勢隆, 清水遼平, 伊藤彰則, “スペクトログラムを用いた CycleGAN に基づく高品質ノンパラレル声質変換,” 日本音響学会2020年秋季研究発表会講演論文集, 2020.
[2]: Yi Ren, Chenxu Hu, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao and Tie-Yan Liu, “FastSpeech 2: Fast and high-quality end-to-end text-to-speech,” In Proc. ICLR, 2021.
[3]: Min-Jae Hwang, Ryuichi Yamamoto, Eunwoo Song and Jae-Min Kim, “High-fidelity Parallel WaveGAN with multi-band harmonic-plus-noise model,” In Proc. INTERSPEECH (in press), 2021.